¿De qué se trata DocETL?
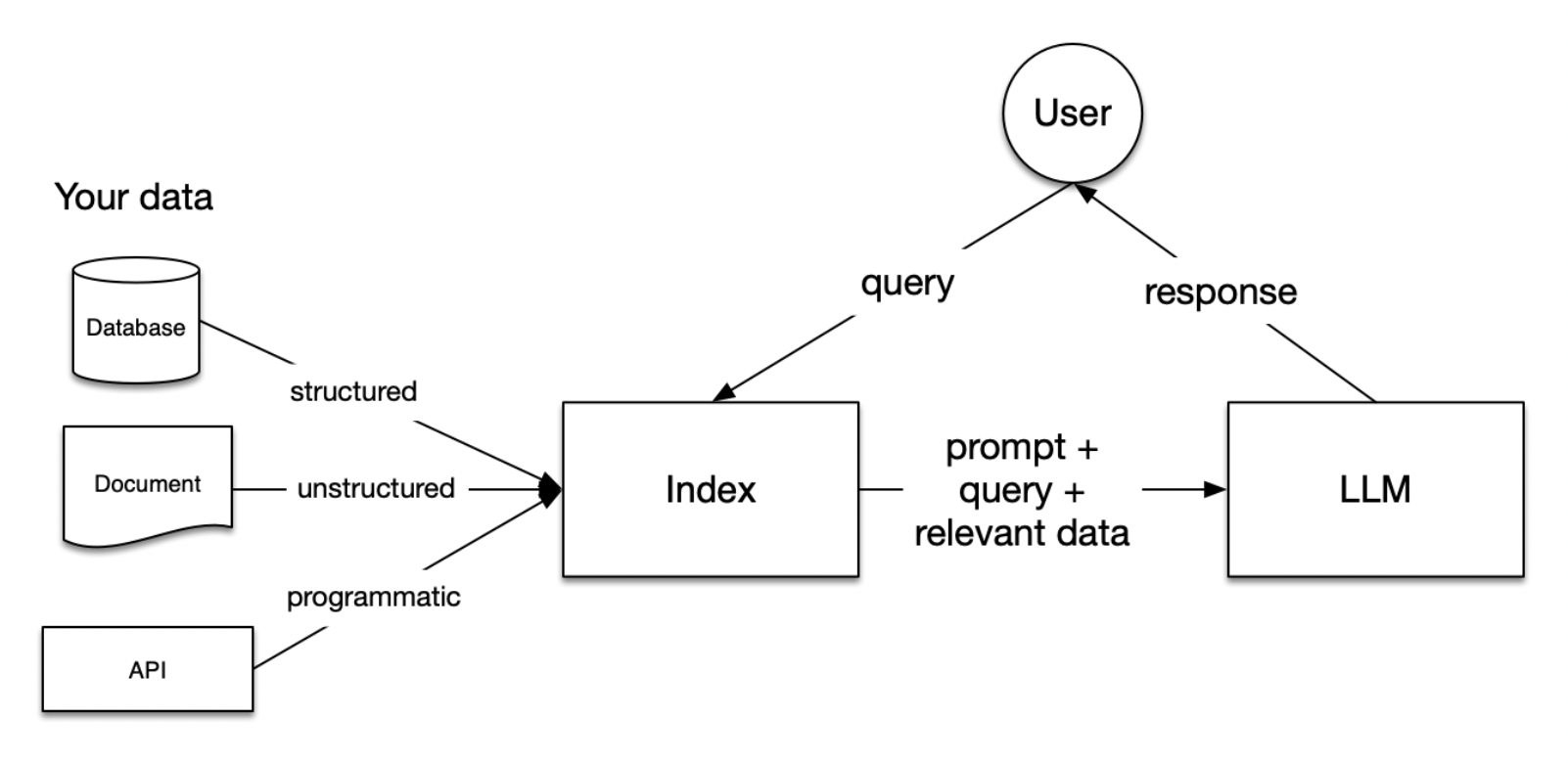
DocETL is a novel system designed to optimize complex document processing pipelines for accuracy by leveraging Large Language Model (LLM) agents
DocETL sirve para procesar grandes cantidades de texto, existen varios procesamientos que se le pueden hacer al texto Leer más …